Artificial Intelligence
Computer Vision Literature Trends: Insights and Perspectives for 2025
Reflecting on Five Years of Computer Vision Trends: A Look at 2024
For the past five years, I’ve closely followed the evolving landscape of computer vision (CV) and image synthesis research, particularly through platforms like Arxiv. Over time, discernible trends emerge, shifting in new directions each year. As 2024 comes to a close, I wanted to share some observations on the latest developments in the Computer Vision and Pattern Recognition section of Arxiv. While these insights are based on extensive engagement with the field, they remain anecdotal.
The Growing Influence of East Asia
By the end of 2023, it was clear that China and other regions in East Asia dominated the ‘voice synthesis’ research category. In 2024, this trend has expanded to include image and video synthesis, with a significant volume of contributions originating from these areas.
This isn’t to suggest that East Asian research always represents the pinnacle of innovation—some evidence points to the contrary. Moreover, proprietary advancements in China and elsewhere likely remain outside the realm of academic literature, much as they do in the West.
However, East Asia’s growing output signals its dominance in sheer volume. Whether this translates into long-term success depends on how one views the persistence model of innovation, famously advocated by Edison. While tenacity can yield progress, it often falters against fundamental challenges requiring entirely new paradigms.
Generative AI, in particular, faces numerous such roadblocks. It’s unclear whether these can be resolved through incremental improvements or if they demand a complete architectural overhaul.
Quantity vs. Quality
The increased output from East Asian researchers has also brought a rise in what might be termed “Frankenstein” projects—studies that combine previous works with limited architectural innovation or merely apply existing techniques to new datasets.
In 2024, many papers from this region (predominantly Chinese or involving Chinese collaborations) appeared quota-driven rather than merit-based, adding to the signal-to-noise ratio in an already saturated field.
Yet, despite this, I’ve also encountered a greater number of East Asian papers this year that captured my attention and admiration. If research is a numbers game, this strategy isn’t failing—but neither is it without cost.
Final Thoughts
As we look to the future, the balance between innovation and volume remains a critical challenge for the global computer vision research community. East Asia’s increasing presence is reshaping the field, bringing both opportunities and questions about how best to navigate this dynamic and rapidly evolving landscape.
Rising Submission Volumes
The sheer volume of paper submissions, regardless of their country of origin, has noticeably increased in 2024.
Submission patterns reveal shifting trends throughout the year, with Tuesdays currently emerging as the most popular day for uploading to the Computer Vision and Pattern Recognition section. During peak periods—typically May through August and October through December, coinciding with conference season and end-of-year quota deadlines—submissions frequently reach 300-350 papers in a single day.
Arxiv itself reported a record-breaking milestone in October 2024, with a staggering 6,000 new submissions across all categories. Among these, the Computer Vision and Pattern Recognition section ranked second in volume, trailing only the Machine Learning category.
However, given that the Machine Learning section often serves as an umbrella category for aggregated or interdisciplinary works, this suggests that Computer Vision and Pattern Recognition might actually represent the most active single domain on Arxiv.
Supporting this trend, Arxiv’s internal statistics highlight computer science as the undisputed leader in overall submissions, further cementing the prominence of the field.
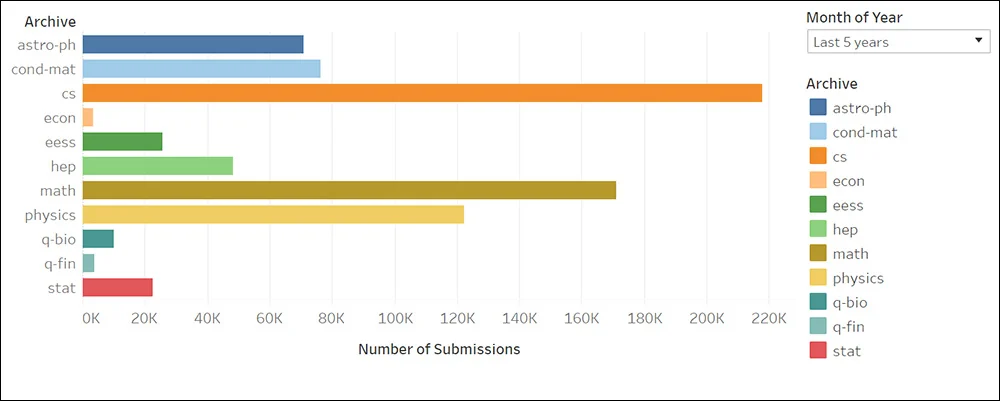
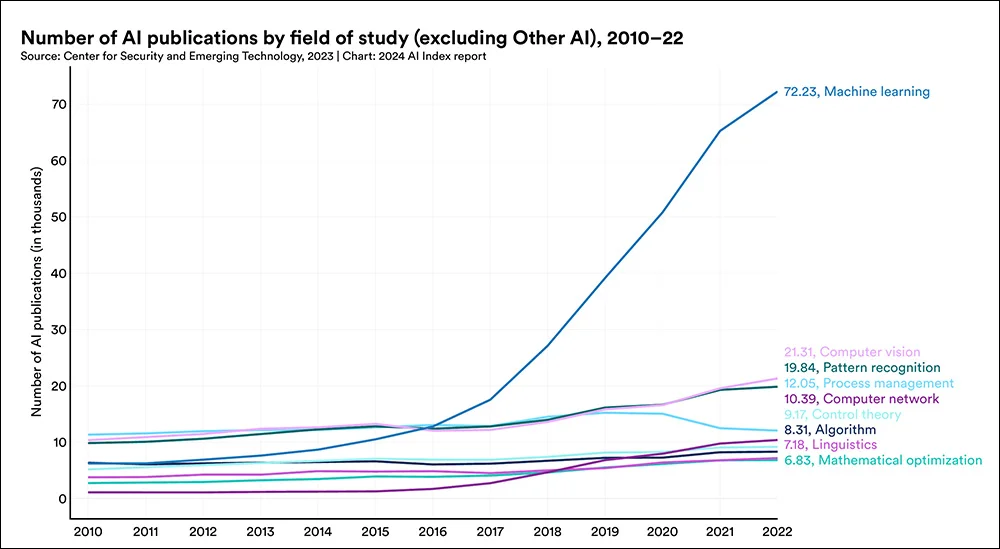
Stanford University's 2024 AI Index, while not yet reporting the most up-to-date statistics, highlights the significant growth in academic paper submissions related to machine learning in recent years:
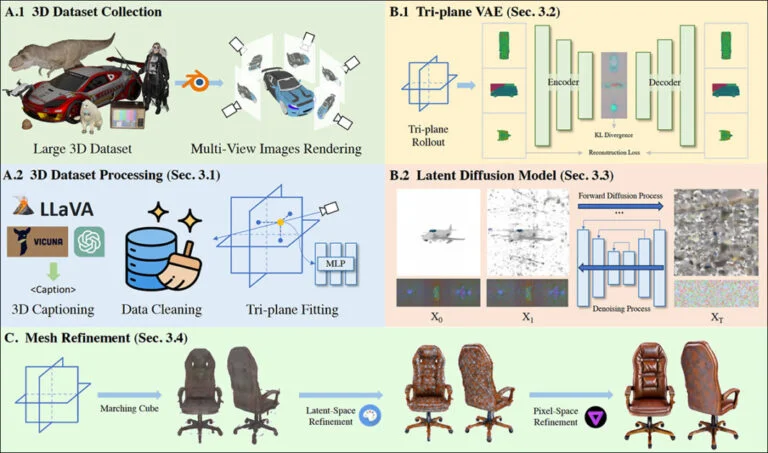
Proliferation of Diffusion-to-Mesh Frameworks
Another prominent trend in 2024 is the surge in papers exploring the use of Latent Diffusion Models (LDMs) to generate mesh-based, traditional CGI models.
Notable projects in this domain include Tencent's InstantMesh3D, 3Dtopia, Diffusion2, V3D, MVEdit, and GIMDiffusion, alongside a growing array of similar innovations.
Diffusion Models: From Frontier to Tool
This emerging line of research may reflect an implicit acknowledgment of the persistent challenges faced by generative systems like diffusion models. Just two years ago, these models were heralded as potential replacements for traditional workflows. Now, diffusion-to-mesh approaches are redefining their role as tools within technologies and workflows that have existed for over three decades.
Stability.ai, creators of the open-source Stable Diffusion model, recently introduced Stable Zero123. Among its capabilities is the use of Neural Radiance Fields (NeRF) to interpret an AI-generated image as a foundation for creating explicit, mesh-based CGI models. These models can be integrated into CGI environments like Unity, as well as video games, augmented reality platforms, and other applications requiring explicit 3D coordinates, as opposed to the implicit (hidden) coordinates used in continuous functions.
![[ soy.lab ] Stable ZERO123 으로 3D 모델링을 만들어보자!? #PART.1](https://i.ytimg.com/vi/RxsssDD48Xc/hqdefault.jpg)
3D Semantics in Generative AI
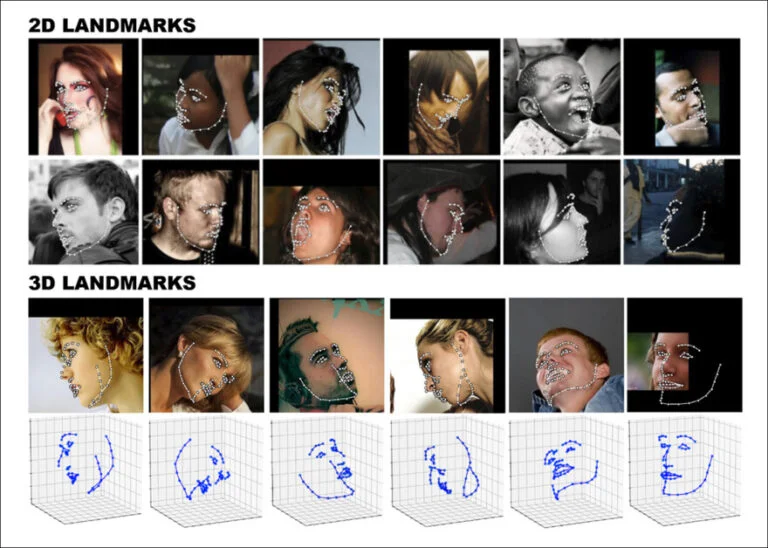
In the generative AI domain, a clear distinction exists between 2D and 3D implementations of vision and generative systems. For example, facial landmarking frameworks, while representing 3D objects such as faces, do not always compute addressable 3D coordinates.
The widely-used FANAlign system, popular in 2017-era deepfake architectures and beyond, is versatile enough to support both 2D and 3D approaches:
The Evolving Terminology of “3D” in Computer Vision
Much like the term “deepfake,” the term “3D” has become ambiguous and context-dependent in computer vision research.
For consumers, “3D” typically refers to stereo-enabled media, such as movies requiring special glasses. For visual effects artists and modelers, it distinguishes 2D conceptual artwork from mesh-based models manipulated in 3D programs like Maya or Cinema4D.
In computer vision, however, “3D” usually means that a Cartesian coordinate system exists within the model's latent space. This does not guarantee that the coordinates can be directly accessed or manipulated without the aid of third-party systems like 3DMM or FLAME.
As a result, the term “diffusion>3D” is somewhat misleading. Any image, including real photographs, can serve as input to generate a CGI model. The term “mesh” is more precise, though diffusion-based systems are often required to translate source images into meshes. A clearer description might be “image-to-mesh,” or more explicitly, “image>diffusion>mesh,” though such technical accuracy might not resonate in boardrooms or investor pitches.
Signs of Architectural Stalemates
The limitations of diffusion-based models have become more pronounced over the last year, with many papers in 2024 highlighting ongoing challenges rather than groundbreaking solutions.
A major obstacle remains the inability to generate narratively and temporally consistent video. Ensuring characters and objects maintain consistent appearances—whether across multiple clips or even within a single short clip—continues to challenge researchers.
The most significant breakthrough in diffusion-based synthesis was the introduction of LoRA in 2022. While newer systems like Flux have addressed specific issues, such as Stable Diffusion's struggles with embedding text into images and improving overall quality, most recent advancements feel incremental. Many of the 2024 papers seem to “move the food around on the plate” rather than introducing transformative innovations.
This stagnation echoes similar plateaus experienced by Generative Adversarial Networks (GANs) and Neural Radiance Fields (NeRF). Both technologies, initially celebrated for their revolutionary potential, now often find application in more conventional systems. For instance, NeRF has been integrated into Stable Zero123 to aid in generating mesh-based models. A similar trajectory seems to be unfolding for diffusion models, as their applications become increasingly practical but less groundbreaking.
Gaussian Splatting Research Shifts Focus
At the close of 2023, the rasterization technique known as 3D Gaussian Splatting (3DGS)—originally developed for medical imaging in the early 1990s—seemed poised to revolutionize human image synthesis. Applications such as facial simulation, recreation, and identity transfer appeared set to surpass autoencoder-based systems.
Notable works like the 2023 ASH paper, which showcased full-body 3DGS humans, and Gaussian Avatars, which demonstrated remarkable detail and cross-reenactment capabilities, fueled expectations for rapid advancements in 2024.
However, breakthrough moments in 3DGS human synthesis have been scarce this year. Many of the papers either iterated on previous works without surpassing their achievements or failed to break new ground.
Instead, research efforts have shifted towards refining the foundational architecture of 3DGS. This pivot has resulted in a wave of papers focused on exterior environments, particularly through Simultaneous Localization and Mapping (SLAM) methods. Projects like Gaussian Splatting SLAM, Splat-SLAM, Gaussian-SLAM, and DROID-Splat exemplify this trend.
Attempts to push splat-based human synthesis further included projects such as MIGS, GEM, EVA, OccFusion, FAGhead, HumanSplat, GGHead, HGM, and Topo4D. While these efforts are commendable, none have matched the disruptive impact of late-2023 innovations.
The Gradual Decline of the ‘Weinstein Era' in Test Samples
A noticeable issue in Southeast Asian, particularly Chinese, generative AI research has been the prevalence of “spicy” or borderline inappropriate test samples. Over the past 18 months, many studies have used examples featuring young, scantily-clad women and girls, making these projects difficult to cite or feature in reviews.
Examples include papers like UniAnimate, ControlNext, and Evaluating Motion Consistency by Fréchet Video Motion Distance (FVMD), which feature borderline NSFW content. This trend mirrors the behavior of online communities surrounding Latent Diffusion Models (LDMs), where content often adheres to Rule 34 principles.
Celebrity Likeness Exploitation
This issue overlaps with another growing concern: the unethical use of celebrity likenesses in AI research. Many studies exploit the images of well-known personalities, often placing them in questionable or objectifying contexts.
For instance, the project AnyDressing not only features very young, anime-style female characters but also includes celebrities such as Marilyn Monroe and Anne Hathaway. Hathaway, in particular, has vocally criticized the use of her likeness in such contexts, reflecting broader ethical concerns about the misuse of public figures' identities in AI-generated content.
Final Thoughts
These trends highlight the need for clearer ethical guidelines in generative AI research, particularly regarding the selection of test samples and the responsible use of identifiable imagery. As the field advances, addressing these issues will be crucial for maintaining credibility and fostering trust in AI applications.

In Western research papers, this practice has noticeably declined throughout 2024, particularly among major releases from FAANG companies and prominent research organizations like OpenAI. Increasingly mindful of potential legal challenges, these corporate leaders are demonstrating a growing reluctance to depict even fictional photorealistic individuals in their outputs.
Although systems like Imagen and Veo2 are evidently capable of generating such content, examples from Western generative AI projects now lean heavily toward “safe” and sanitized imagery—often featuring stylized, “cute,” and Disney-like aesthetics in both images and videos.

Face-Washing in Western CV Literature
In Western computer vision literature, a notable trend is the practice of “face-washing” in customization systems—methods designed to generate consistent likenesses of a specific person across various examples (such as LoRA and the older DreamBooth).
This trend is evident in systems like orthogonal visual embedding, LoRA-Composer, Google's InstructBooth, and many others. These approaches often prioritize sanitized or abstracted representations, avoiding direct or controversial likenesses in favor of more generalized outputs.

The Rise of the ‘Cute Example’ in CV and Synthesis Research
The growing trend of “cute” examples is evident across various computer vision and synthesis research fields, seen in projects like Comp4D, V3D, DesignEdit, UniEdit, FaceChain (which acknowledges more realistic user expectations on its GitHub page), and DPG-T2I, among many others.
The accessibility of systems like LoRA, which can be created by home users with relatively modest hardware, has led to a surge in freely downloadable celebrity models within the civit.ai domain and community. Such illicit use continues to thrive, fueled by the open-source nature of architectures like Stable Diffusion and Flux.
While it is possible to bypass the safety features of generative text-to-image (T2I) and text-to-video (T2V) systems to produce content that violates platform terms of service, the gap between the restricted capabilities of leading systems (like RunwayML and Sora) and the unrestricted power of more basic systems (like Stable Video Diffusion, CogVideo, and local deployments of Hunyuan) is not closing, contrary to what some might expect.
Instead, both proprietary and open-source systems are at risk of becoming similarly ineffective. Expensive, hyperscale T2V systems may become overly constrained due to fears of legal repercussions, while open-source systems, lacking proper licensing infrastructure and dataset oversight, could be locked out of the market as more stringent regulations are introduced.